Partition and Sharding is the method to scale out your database when you are dealing with huge volume of data. Table partition and sharding come up with pros and cons, it is the technique to break data table in to multiple pieces and spread them across databases. It will improve database performance and query runtime to be more faster. I think post I'll demonstrate how to partition table and sharding table.
Table Partitioning
First, I will talking about table partitioning.Partitioning concept is about split data table in to multiple table and spread those table to different database.

|
|
Fig 02. Table Partitioning |
Postgresql provide built-in function to create table partition in the database. In postgreSQL 12, partitioning comes with three options as below.
- Range - Partitioning
- List - Partitioning
- Hash - Partitioning
Table is partitioned by range of key column or set of key columns.
The table is partitioned by listing which key values appear in each partition.
The table is partitioned by specifying a modulus and a remainder for each partition
Range Partitioning
First, we will try with range partition. It is the simplest method, you can create table with range partition as below
/* CREATE USER TABLE PARTITION BASE ON CREATEDATE */
create table if not exists USERTBL(
USRID SERIAL not
null,
USRNAME VARCHAR(180) not
null ,
FIRSTNAME VARCHAR(128) not
null,
LASTNAME VARCHAR(128) not
null,
CREATEDATE DATE not
null,
primary key (USRID,
CREATEDATE)
) PARTITION BY RANGE (CREATEDATE);
CREATE TABLE USERTBL_2017 PARTITION OF USERTBL
FOR VALUES FROM ('2017-01-01') TO
('2017-12-31');
CREATE TABLE USERTBL_2018 PARTITION OF USERTBL
FOR VALUES FROM ('2018-01-01') TO
('2018-12-31');
CREATE TABLE USERTBL_2019 PARTITION OF USERTBL
FOR VALUES FROM ('2019-01-01') TO
('2019-12-31');
Then we use below script to insert data to the table
/* INSERT DATA TO TABLE FOR RANGE PARTITION */
do $$
<<FIRSTBLOCK>>
declare
PUSRNAME VARCHAR ;
C INTEGER;
PCREATEDATE1 DATE := date
'2017-03-18' ;
PCREATEDATE2 DATE := date
'2018-04-18' ;
PCREATEDATE3 DATE := date
'2019-05-18' ;
begin
/* */
for C in 1..9 LOOP
pusrname := '000'|| cast (C
as VARCHAR);
PCREATEDATE1 := PCREATEDATE1
+ C;
insert into usertbl
(usrname,firstname,lastname,createdate ) values
(pusrname,'firstname','lastname', PCREATEDATE1);
end loop;
/* */
for C in 10..19 LOOP
pusrname := '00'|| cast (C as
VARCHAR);
PCREATEDATE2 := PCREATEDATE2
+ C -10;
insert into usertbl
(usrname,firstname,lastname,createdate ) values
(pusrname,'firstname','lastname', PCREATEDATE2);
end loop;
/* */
for C in 20..29 LOOP
pusrname := '00'|| cast (C as
VARCHAR);
PCREATEDATE3 := PCREATEDATE3
+ C - 20;
insert into usertbl
(usrname,firstname,lastname,createdate ) values
(pusrname,'firstname','lastname', PCREATEDATE3);
end loop;
commit;
end FIRSTBLOCK $$;
After we ran the script, we will see as below.
usr01=> \d+ usertbl
Partitioned table "usr01.usertbl"
Column |
Type | Collation | Nullable
|
Default
| Storage | Stats target | Description
------------+------------------------+-----------+----------+----------------------------------------+----------+--------------+-------------
usrid | integer
|
| not null | nextval('usertbl_usrid_seq'::regclass) |
plain |
|
usrname | character varying(180) |
| not null |
| extended |
|
firstname | character varying(128) |
| not null |
| extended |
|
lastname | character varying(128) |
| not null |
| extended |
|
createdate | date
|
| not null |
| plain |
|
Partition key: RANGE (createdate)
Indexes:
"usertbl_pkey" PRIMARY KEY, btree (usrid,
createdate)
Partitions: usertbl_2017 FOR VALUES FROM ('2017-01-01') TO
('2017-12-31'),
usertbl_2018 FOR VALUES
FROM ('2018-01-01') TO ('2018-12-31'),
usertbl_2019 FOR VALUES
FROM ('2019-01-01') TO ('2019-12-31')
Table has been created along with the partition by range. And after we inserted the data into the table if we look into table partition, we will see as below result.
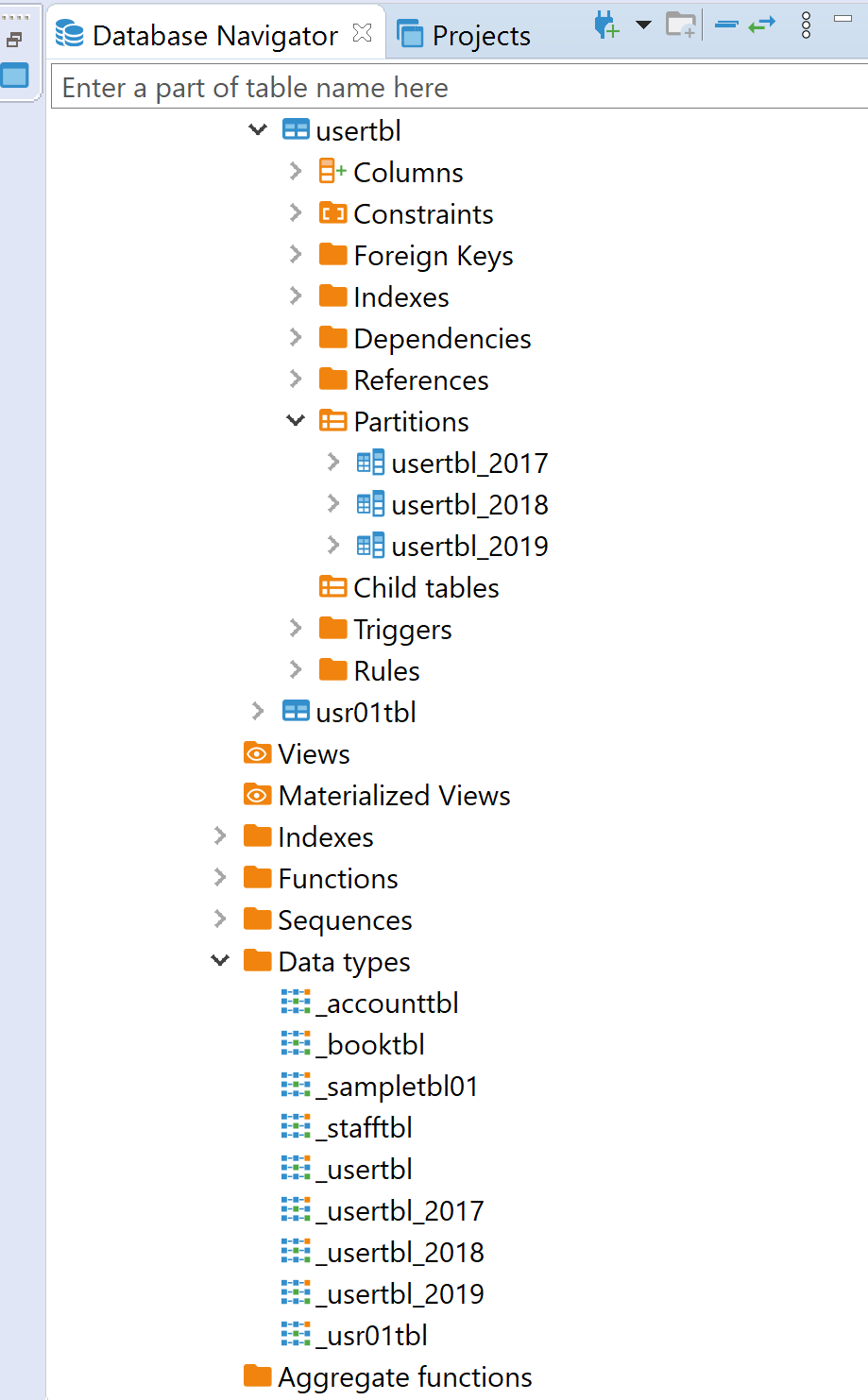
|
|
Fig 03 Table Partition Detail |
And we can check each partition table and we can see as following.

|
|
Fig 04 Partition table for 2017 |

|
|
Fig 05 Partition Table for 2018 |
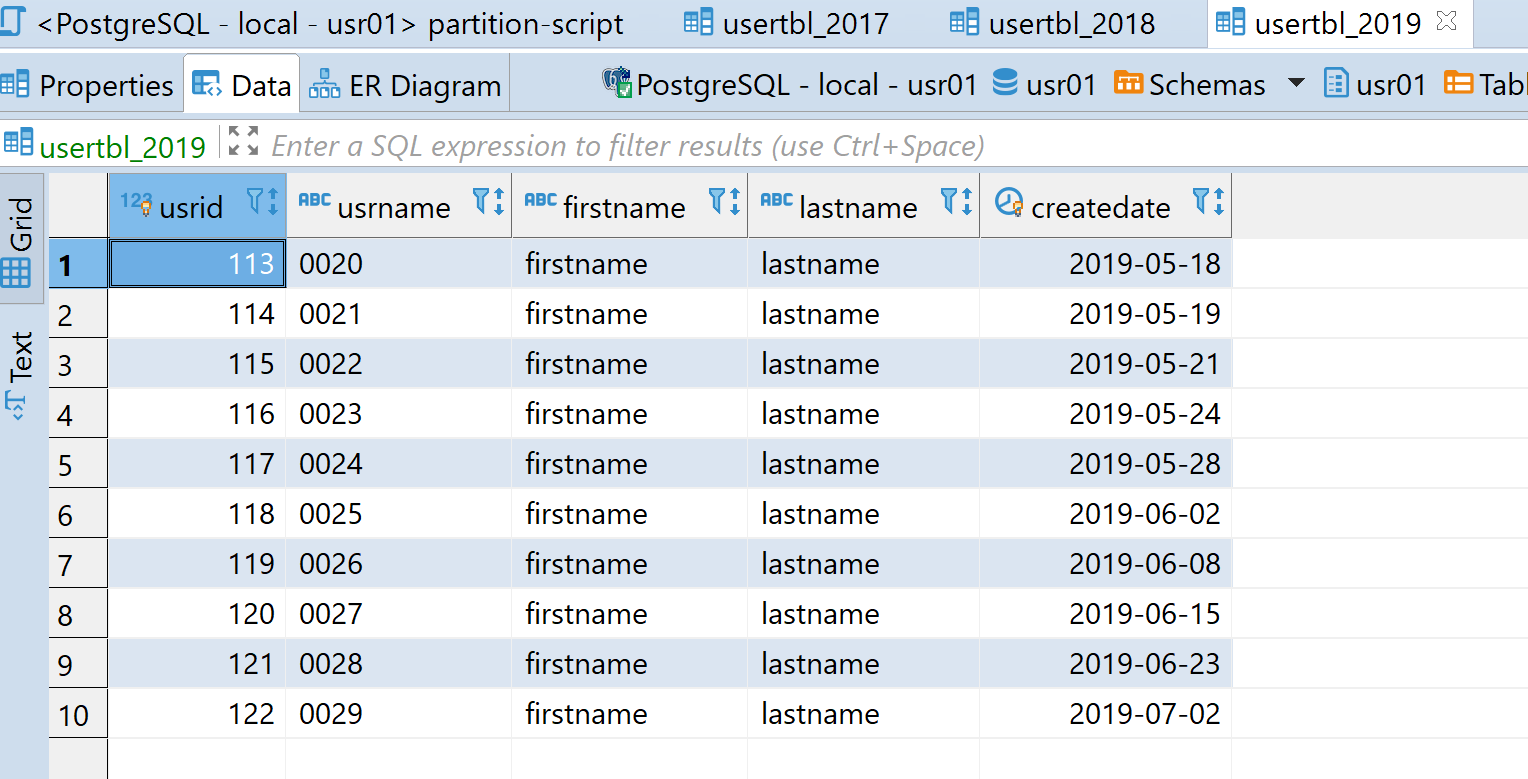
|
|
Fig 06 Partition Table for 2019 |
List Partition
A list partition is created with predefined values to hold in a partitioned table. A default partition (optional) holds all those values that are not part of any specified partition.For example, you create a table and you want to partition table base on some columns (e.g.status) value (e.g.'active','expired'). You can create a table as following example.
CREATE TABLE IF NOT EXISTS RECORDTBL (
RCDID SERIAL NOT NULL,
DESCR VARCHAR(128),
CREATEDATE TIMESTAMP DEFAULT
NOW(),
STATUS VARCHAR(128)
) PARTITION BY LIST(STATUS);
CREATE TABLE IF NOT EXISTS RECORDTBL_ACTIVE PARTITION OF RECORDTBL
FOR VALUES IN ('ACTIVE');
CREATE TABLE IF NOT EXISTS RECORDTBL_EXPIRED PARTITION OF RECORDTBL
FOR VALUES IN ('EXPIRED');
Next, we can check created table and its partition as below
sampledb=> \d+ sample.RECORDTBL;
Table "sample.recordtbl"
Column |
Type | Collation
| Nullable |
Default
| Storage | Stats target |
Description
------------+-----------------------------+-----------+----------+-------------------------------------------------+----------+--------------+-------------
rcdid | integer
|
| not null |
nextval('sample.recordtbl_rcdid_seq'::regclass) | plain
| |
descr | character varying(128)
| |
|
| extended |
|
createdate | timestamp without time zone |
| | now()
| plain |
|
status | character varying(128)
| |
|
| extended |
|
Partition key: LIST (status)
Partitions: sample.recordtbl_active FOR VALUES IN ('ACTIVE'),
sample.recordtbl_expired
FOR VALUES IN ('EXPIRED')
Then we insert records in to the table as below script.
DO $$
<<sample_block>>
DECLARE
counter integer := 0;
BEGIN
FOR i IN 1..100 LOOP
counter :=
counter + 1;
IF counter % 2 =
1 THEN
--RAISE NOTICE
'The current value of counter is %', counter;
INSERT INTO
RECORDTBL(DESCR, STATUS) VALUES ('SAMPLE','ACTIVE');
ELSE
--RAISE NOTICE
'The current value of counter is ---';
INSERT INTO
RECORDTBL(DESCR, STATUS) VALUES ('SAMPLE','EXPIRED');
END IF;
END LOOP;
END sample_block $$;
We can check as below result.

|
|
Fig 07. List Partition |
Hash Partition
A hash partition is created by using modulus and remainder for each partition, where rows are inserted by generating a hash value using these modulus and remainders.
CREATE TABLE IF NOT EXISTS RECORDTBL(
CRDID SERIAL,
STATUS VARCHAR(128),
ARR INTEGER
) PARTITION BY HASH(CRDID);
CREATE TABLE IF NOT EXISTS RECORDTBLP00 PARTITION OF RECORDTBL FOR
VALUES WITH (modulus 3, remainder 0);
CREATE TABLE IF NOT EXISTS RECORDTBLP01 PARTITION OF RECORDTBL FOR
VALUES WITH (modulus 3, remainder 1);
CREATE TABLE IF NOT EXISTS RECORDTBLP02 PARTITION OF RECORDTBL FOR
VALUES WITH (modulus 3, remainder 2);
Then we create script to insert records as following.
DO $$<<SAMPLEBLOCK>>declare C INTEGER := 0;begin
for C in 1..100 LOOP C := C+1; INSERT INTO RECORDTBL (STATUS,ARR) VALUES ('ACTIVE',C); end loop;
commit;
end SAMPLEBLOCK $$;
And we can see the partition tables as below.

|
|
Fig 08 Hash Partition |
No comments:
Post a Comment